

Do you regularly find yourself down a YouTube rabbit hole, wading through the hours of content that is effortlessly served to you? This is not accidental. Over 70% of content consumed on YouTube comes from its recommendation engine - this system is engineered to keep you watching more and more videos.
YouTube’s recommender system represents one of the biggest and most sophisticated recommendation systems in the world and is a vital lynchpin in the success of the world’s largest content platform.
So how exactly does YouTube’s recommendation system work?
To understand how YouTube’s recommendation system works, we have to look at three issues YouTube has to solve to provide its customers with a best in class recommendation experience.
1. Scale
There are over 800 million videos on YouTube. Any existing recommendation algorithms proven to work reasonably efficiently on small data sets, like comparing user profiles, do not work on a data set this large.
2. The cold-start problem
The cold-start problem exists where we have little to no behavioural data when an item or piece of content is uploaded to a platform - we are unable to recommend these items to users.
Susan Wojcicki, YouTube’s CEO, made the cold-start problem very apparent back in February 2020 when she declared there were two billion monthly YouTube users around the world, and 500 hours of video uploaded every minute. This is a figure likely to have been inflated in a society that has endured a Covid-19 induced lockdown for the past 12-18 months.
3. Data noise
With over 800 million videos on YouTube, there are inevitably many videos with extremely sparse historical user behaviour data. As a result, these videos are less likely to surface as a recommendation.
YouTube can also rarely obtain the ground truth of user satisfaction and instead has to model noisy implicit feedback signals. We will go into why explicit signals are an ineffectual measurement of user satisfaction when it comes to a recommendation system later on in this blog post.
Issues with noisy implicit data becomes a double edged sword when you take into account the textual data associated with content (titles, descriptions etc). This is infamously poor because it is uploaded by content creators themselves.
YouTube’s recommendation system
To counteract these issues, YouTube operates two neural networks (a set of algorithms, modelled loosely after the human brain, that are designed to recognize patterns) through a deep collaborative filtering model (more on this shortly).
This collaborative filtering model is able to effectively understand many signals and model signal overlap with layers of depth to narrow down from 800 million videos to recommend you, an individual user, dozens of hyper personalised video recommendations, in real time.
See an infographic of this model below:

Item-item collaborative filtering
Item-item collaborative filtering is the division of machine learning that YouTube uses to create these hyper-personalised recommendations. This technology is also used by retail giants like Amazon and retail technology companies like Particular Audience.
Item-item collaborative filtering matches each of YouTube’s user’s implicitly rated items (content clicked on and watched) to similar items and then compiles those similar items into a recommendation list.

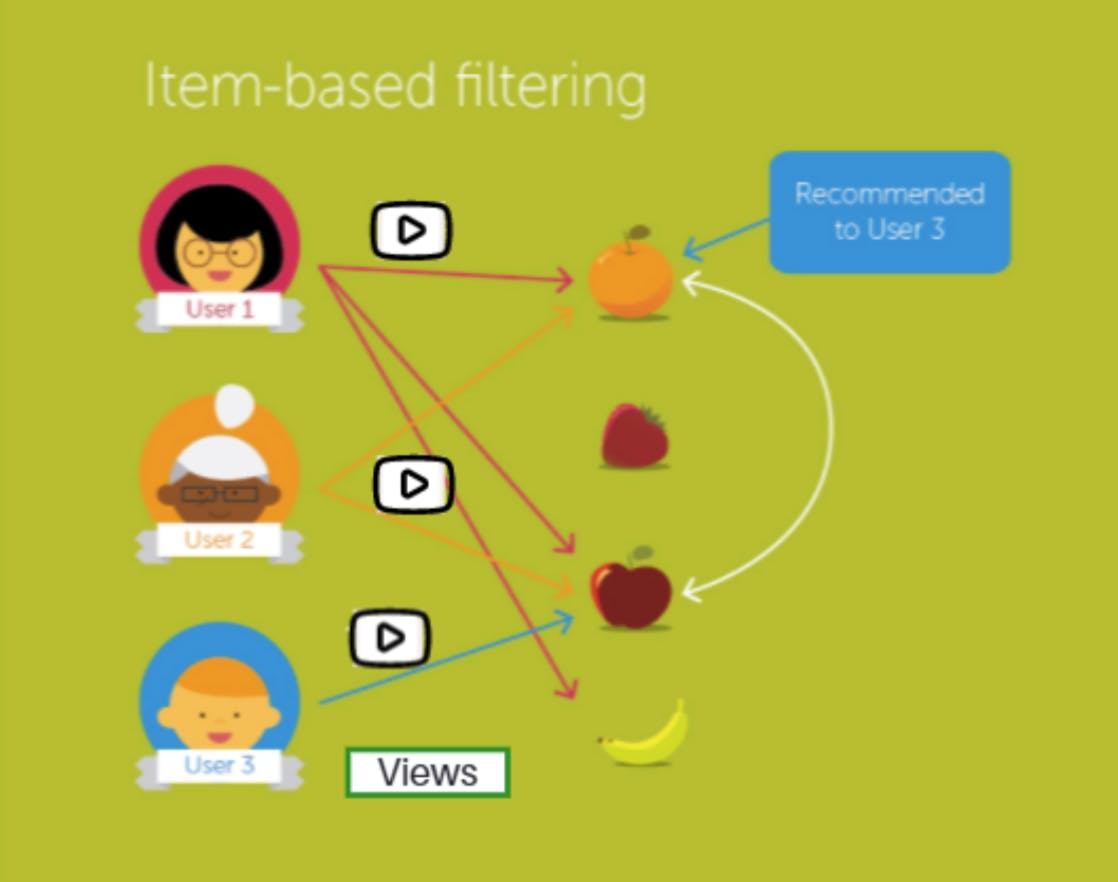
To determine the most-similar match for a given piece of content, the algorithm builds a similar-items table (or matrix) by finding items that customers tend to watch together. This looks like a video-to-video matrix, built by cross-referencing all item pairs and computing a similarity metric (a numerical score from 0 to 1) for each pair.
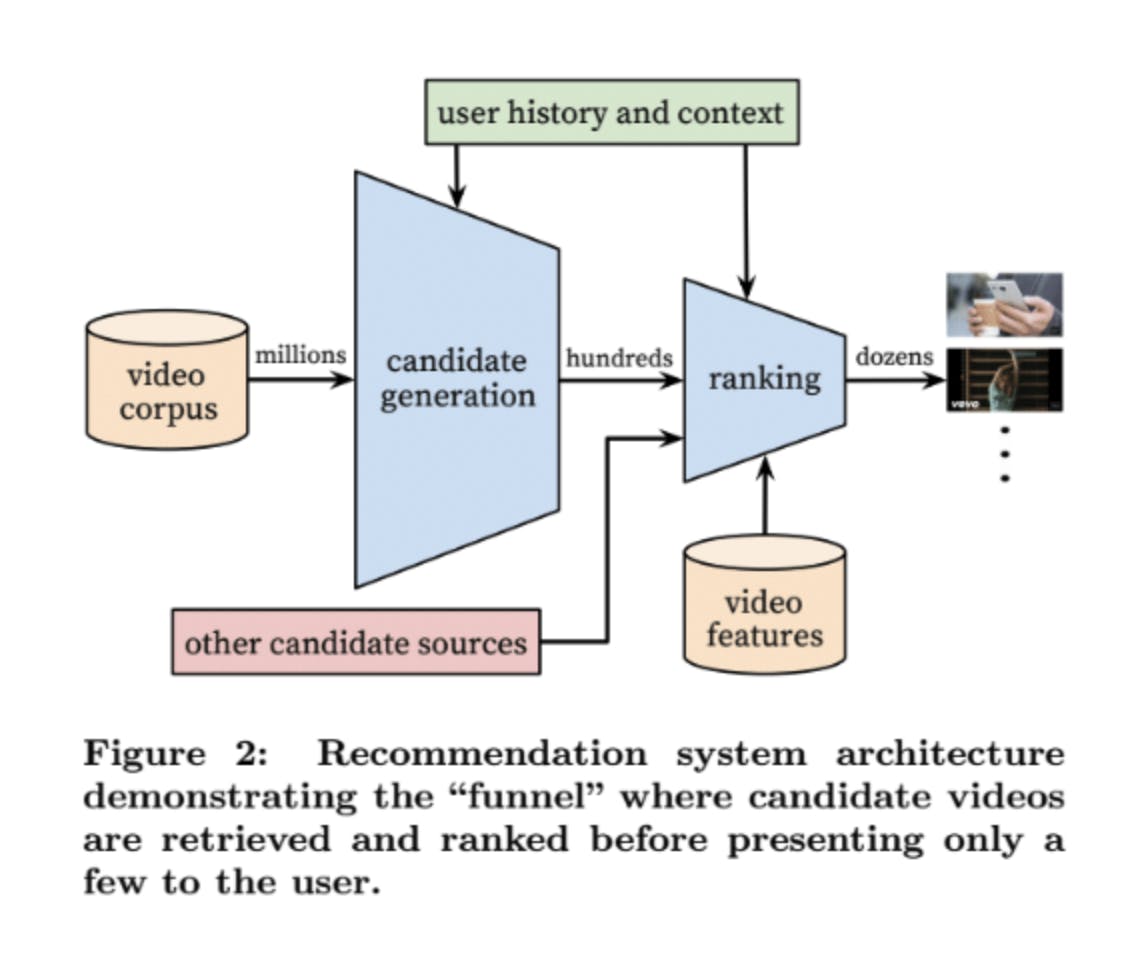
To get this personalised content to each user, YouTube’s personalisation algorithm must filter 800 million videos down to a few dozen. The initial process that narrows this corpus down is referred to by YouTube as “candidate generation”.
Candidate generation
This is YouTube's process of whittling down 800 million videos down to a few hundred.
The candidate generation network takes events from a user’s YouTube activity history as input and retrieves a small subset (hundreds) of videos from YouTube’s large catalogue.
These video candidates are intended to be generally relevant to the user with high precision. The candidate generation network only provides broad personalization via collaborative filtering.
Their algorithms use implicit feedback loops (a fully watched video is a positive implicit feedback loop compared to explicit feedback like giving a video a thumbs up or down) because this a much more robust data set.
The cold-start problem during candidate generation
Beyond their behavioural collaborative filtering models, YouTube also needs to solve the issue that over 500 hours of content is being uploaded every minute to the platform.
If YouTube only used behavioural algorithms, these new pieces of content can’t be served up as a recommendation until they are sufficiently clicked on and watched. This is a huge problem because some of this new content will be very relevant for viewers and it would be damaging for the user experience if this content wasn’t recommended.
The problem of getting this new content to the relevant users is called the cold-start problem.
YouTube solves the cold-start problem using models that compare similarities between text such as Natural Language Processing.
YouTube must create a representation for keywords and textual data from the videos being uploaded that capture their meanings, semantic relationships and the different types of contexts they are used in. These word relationships are utilised by using numerical representations of texts so that computers may handle them (a method known as Word Embeddings).
As YouTube pulls keywords and attributes from videos, Word Embedding allows YouTube to compute similar words, create a group of related words (to compare similar content) and then cluster these into groups. This enables YouTube to rank videos by similarities in their content and recommend similar alternatives.
Crucially, this process doesn’t require any behavioural data to compute, solving the cold-start problem.
Other factors during candidate generation
YouTube will also consider factors such as a user’s previously watched videos, what the user has searched for in the past, information on a user’s demographic and their location to optimise the candidate generation process.
Once candidate generation has filtered through YouTube’s full video catalogue, the next stage of their process is the “ranking” neural network.
Ranking
This is the process whereby YouTube’s algorithm whittles down the hundreds of generated content “candidates” to dozens of hyper personalised video recommendations.
The ranking network achieves this by assigning a score to each video according to a desired objective function. Ranking will be given using a rich set of features describing the video and user with the highest scoring videos being presented to the user.
The primary role of ranking is to use impression data to specialize and calibrate candidate predictions for an individual user.
YouTube says that the most important signals are those that describe a user’s previous interaction with the item itself and other similar items, matching others’ experience in ranking videos.
As an example, YouTube considers the user’s past history with the specific channel that uploaded the video being scored, how many videos the user has watched from this channel and/or how long ago the user last watched a video on this topic.
These continuous features describing past user actions on related items are particularly powerful because they generalize well across mostly incomparable items.
Word Embeddings in the ranking phase
Similar to candidate generation, YouTube continues to utilise Word Embeddings to solve the cold-start problem. They map sparse categorical features (coming from video Word Embeddings) to dense representations and categorical clusters suitable for usage in neural networks like that shown in figure 2.
Video churn and negative ranking
During the ranking stage, YouTube will also negatively score factors like video churn to alter their matrix. If a user has recently been recommended a video but did not watch it, then the model will naturally demote this impression on the next page load.
In short
Ultimately, YouTube’s final objective for ranking content is very generally speaking a simple function of expected watch time per impression (impression being a metric used to quantify the number of digital views or engagements of a piece of content). YouTube must use a series of complex neural networks to solve the issues of scale, the cold-start problem and data noise.
Through a combination of advanced item-item collaborative filtering and natural language processing models, YouTube is able to filter down 800 million videos to recommend to you a few dozen videos. Despite having over 800 million videos and 2 billion monthly users on the platform, YouTube provides this personalised experience for each and every visitor that uses YouTube’s platform. This enables users like you and I to spend hours of our lives perusing their rich bank of content.
To see YouTube’s recommendation in action, see YouTube.
For more technical details on YouTube’s recommender, see this research paper published by Google engineers Paul Covington, Jay Adams, and Emre Sargin.




